文本情感分析(Sentiment Analysis)是自然语言处理(NLP)方法中常见的应用,也是一个有趣的基本任务,尤其是以提炼文本情绪内容为目的的...本文将详细介绍如何使用深度学习模型中的LSTM模型来实现文本的情感分析。
”ai 深度学习 LMDB“ 的搜索结果
深度学习是机器学习领域一个新兴的研究方向,它通过模仿人脑结构,实现对复杂输入数据的高效处理,智能地学习不同的知识,而且能够有效地解决多类复杂的智能问题。实践表明,深度学习是一种高效的特征提取方法,它...
caffe将图片生成lmdb源码,设置好图片的文件夹目录,然后会根据目录生成对应的LMDB和CSV文件。
在前面我们要么是通过module加载conda环境,要么是自己安装的,但是你看,你要么load一下,要么还要激活conda环境,实际上我们把conda安装在home目录之后,python环境也就在这里,我们可以在目录下,写个脚本,后面...
文章首发于 个人博客 文章目录IntroductionZheTeng ConditionsGPU 列表CPU 列表关于 ROCmInstall on Ubuntu系统准备安装 ROCmDeep Learning on ROCmTensorflowPyTorchConclusion Introduction ...
最近在做预训练的时候,需要从视频中提取图片,然后保存在lmdb数据库中。 但是直接储存图片数据会占用很大的内存,所以存储的时候,需要先将图片编码压缩之后,再存储到lmdb数据库;读取的时候,需要读取出来之后再...
Pytorch框架,使用lmdb格式的数据集进行训练时,报错lmdb.InvalidParameterError: Caught InvalidParameterError in DataLoader worker process 0. l读取lmdb文件时,lock设置为False python - lmdb....
使用LMDB 存储形式可以加快IO 和CPU 解压缩的速度。
基于PaddleOcr 身份证识别 (身份证号码、姓名)

4实验结果及设置 4.1数据集 本文采用ICDAR2013,ICDAR2015数据集并将ICDAR2013,ICDAR2015 dataset 转化为 PASCAL_VOC dataset 格式对于模型进行训练和验证。其中ICDAR2013数据集样本多为自然场景水平字符,同时包含...

机械硬盘的情况:机械硬盘的每次读写启动时间比较场,例如磁头的寻道时间占比很高,因此,如果单个小文件读写,尤其是随机读写单个小文件的时候,这个寻道时间占比就会很高,最后导致大量读写小文件的时候时间会很...
人工智能的浪潮正席卷全球,诸多词汇时刻萦绕在我们的耳边,如人工智能,机器学习,深度学习等。“人工智能”的概念早在1956年就被提出,顾名思义用计算机来构造复杂的,拥有与人类智慧同样本质特性的机器。经过几...
深度学习库比较 库名 主语言 从语言 速度 灵活性 文档 适合模型 平台 上手难易 开发者 模式 Tensorflo C++ cuda/python/Matlab/Ruby/R 中等 好 中等 CNN/RNN Linux,OSX 难 Google 分布式/声明...
点击打开链接 (谷歌所有,需科学上网…)在本文将涉及到以下内容:准备数据训练用于图片分类的神经网络(Caffe)Python实现移植树莓派神经网络移植于Intel Movidius 芯片的一款嵌入式智能硬件,弥补树莓派计算力...
精品收藏:GitHub人工智能AI开源项目 绝对精品!!!花了点时间,鄙人把这几年收藏的开源精品项目,整理一下,方面以后查找。其中涵盖了姿态检测,图像分割,图像分类,美学评价、人脸识别、多尺度训练,移动端的AI...
softmax(o)给出的分布⽅差,并与softmax交叉熵损失l(y, yˆ)的⼆阶导数匹配。Softmax函数可以将一组任意实数值转换为一个概率分布,它的输出值是各个类别的概率估计。如果我们用softmax函数得到的概率分布与真实分布...
TensorBoard是用于可视化和调试机器学习模型的工具。它可以帮助跟踪训练过程中的各种指标,例如损失值、准确率等,并查看模型的结构和参数分布。TensorBoard由Google开发,最初用于TensorFlow框架,现在也支持...
数据集:原始数据集中的图片分辨率大小不一,这里在生成lmdb的时候,统一裁剪为160x160的分辨率大小。create_lmdb.sh脚本中使用参数 --resize_height=160 --resize_width=160网络模型: alex net。
文字识别是AI的一个重要应用场景,文字识别过程一般由图像输入、预处理、文本检测、文本识别、结果输出等环节组成。 分类:文字识别可根据待识别的文字特点采用不同的识别方法,一般分为定长文字、不定长文字两大...
【代码】【深度学习】Chinese-CLIP 使用教程,图文检索,跨模态检索,零样本图片分类。
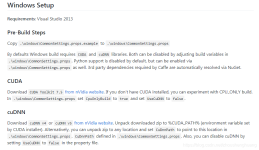
本教程详细记录了使用 caffe 制作 VOC0712 lmdb 数据集的方法。
MMDetection 是一个强大的开源目标检测工具箱,由商汤科技和香港中文大学共同研发维护,它基于PyTorch深度学习框架构建,提供了丰富的目标检测、实例分割、全景分割算法以及相关的组件和模块。本文从深度学习目标...

本文主要讲解caffe的整个使用流程,适用于初级入门caffe,通过学习本篇博文,理清项目训练、测试流程。初级教程,高手请绕道。 我们知道,在caffe编译完后,在caffe目录下会生成一个build目录,在build目录下有个...
no module named 'lmdb'
人工智能的浪潮正席卷全球,诸多词汇时刻萦绕在我们的耳边,如人工智能,机器学习,深度学习等。“人工智能”的概念早在1956年就被提出,顾名思义用计算机来构造复杂的,拥有与人类智慧同样本质特性的机器。经过几...
推荐文章
- c语言课程图书信息管理系统,c语言课程设图书信息管理系统.doc-程序员宅基地
- webpack4脚手架搭建1——打包并编译es6_webpack编译es6语法打包-程序员宅基地
- 信息通信服务、电子商务及物流服务的创新与发展_信息通信,电子商务-程序员宅基地
- websocket.js的封装,包含保活机制,通用_websocket保活-程序员宅基地
- Ubuntu安装conda-程序员宅基地
- LoadRunner性能测试关注指标及结果分析_loadrunner性能指标分析-程序员宅基地
- java怎么做图形界面_java怎么做图形界面?实例分享-程序员宅基地
- eMMC常识性介绍N_emmc温升系数-程序员宅基地
- MATLAB算法实战应用案例精讲-【人工智能】机器视觉(概念篇)(最终篇)-程序员宅基地
- Mac电脑如何串流游戏 Mac上的CrossOver是串流游戏吗 串流游戏是什么意思 串流游戏怎么玩 Mac电脑怎么玩Steam游戏_macos steam和crossover steam区别-程序员宅基地